Hey everyone!
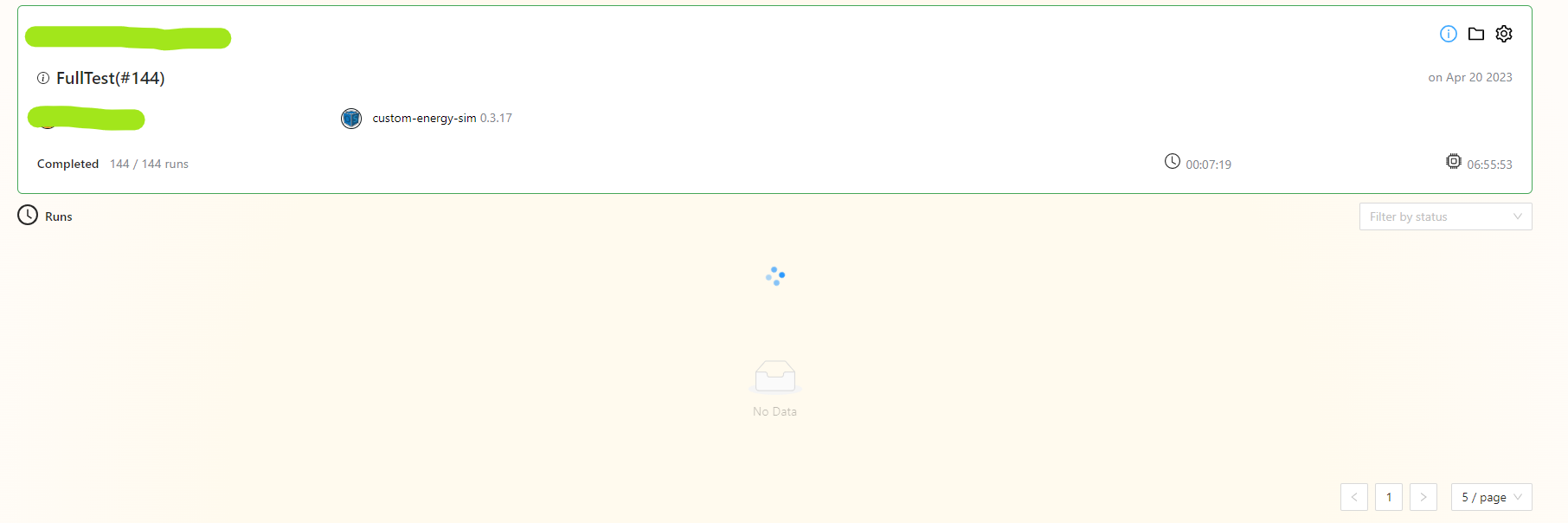
I’ve been loving the convenience of pollination cloud computing for handling intensive simulations! However, we recently encountered an issue during our first full test with custom-energy-sim 0.3.17. Out of the simulations we ran, 143 were successful, but 1 failed.
The logs from the failed run appear unusual, as the simulation seems to have halted unexpectedly without any error messages (I’ve attached the logs after the warm-up below).
Initially, I thought the issue could be due to the simulation exceeding the limits for a single run, but the successful runs were essentially using the same model, with only minor parameter adjustments.
Interestingly, I discovered that some successful runs had also encountered the same issue, but their debug pages indicated that new simulations were started and eventually succeeded.

Could anyone provide some insights on this issue? Additionally, is there a way to re-run the failed simulation within the study instead of creating a new one? The post-processing can get quite messy when trying to combine results from different studies.
Any assistance would be greatly appreciated. Thanks in advance!
143
Starting Simulation at 01/01/2006 for RUN PERIOD 1
144
Updating Shadowing Calculations, Start Date=01/31/2006
145
Continuing Simulation at 01/31/2006 for RUN PERIOD 1
146
Updating Shadowing Calculations, Start Date=03/02/2006
147
Continuing Simulation at 03/02/2006 for RUN PERIOD 1
148
Updating Shadowing Calculations, Start Date=04/01/2006
149
Continuing Simulation at 04/01/2006 for RUN PERIOD 1
150
Updating Shadowing Calculations, Start Date=05/01/2006
151
Continuing Simulation at 05/01/2006 for RUN PERIOD 1
152
Updating Shadowing Calculations, Start Date=05/31/2006
153
Continuing Simulation at 05/31/2006 for RUN PERIOD 1
154
Updating Shadowing Calculations, Start Date=06/30/2006
155
Continuing Simulation at 06/30/2006 for RUN PERIOD 1
156
Updating Shadowing Calculations, Start Date=07/30/2006
157
Continuing Simulation at 07/30/2006 for RUN PERIOD 1
158
Updating Shadowing Calculations, Start Date=08/29/2006
159
Continuing Simulation at 08/29/2006 for RUN PERIOD 1
160
Updating Shadowing Calculations, Start Date=09/28/2006
161
Continuing Simulation at 09/28/2006 for RUN PERIOD 1
162
Updating Shadowing Calculations, Start Date=10/28/2006
163