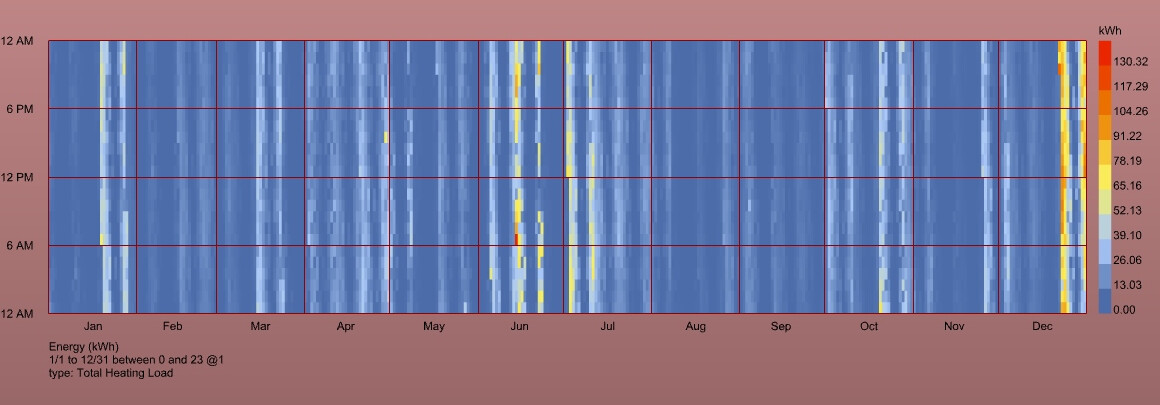
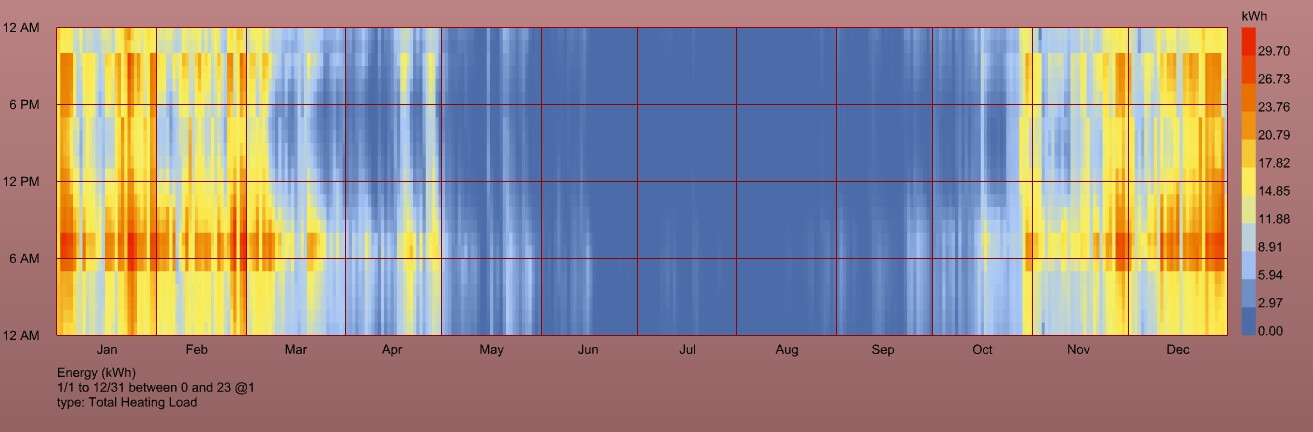
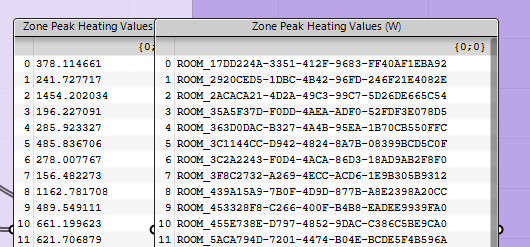
Checking out what goes wrong isn’t much fun since for example it’s really hard to work with such room names. Hope the search function is updated soon and the custom Room names should be also passed trough, shouldn’t they?
But maybe the answer what went wrong is more simple than I think?
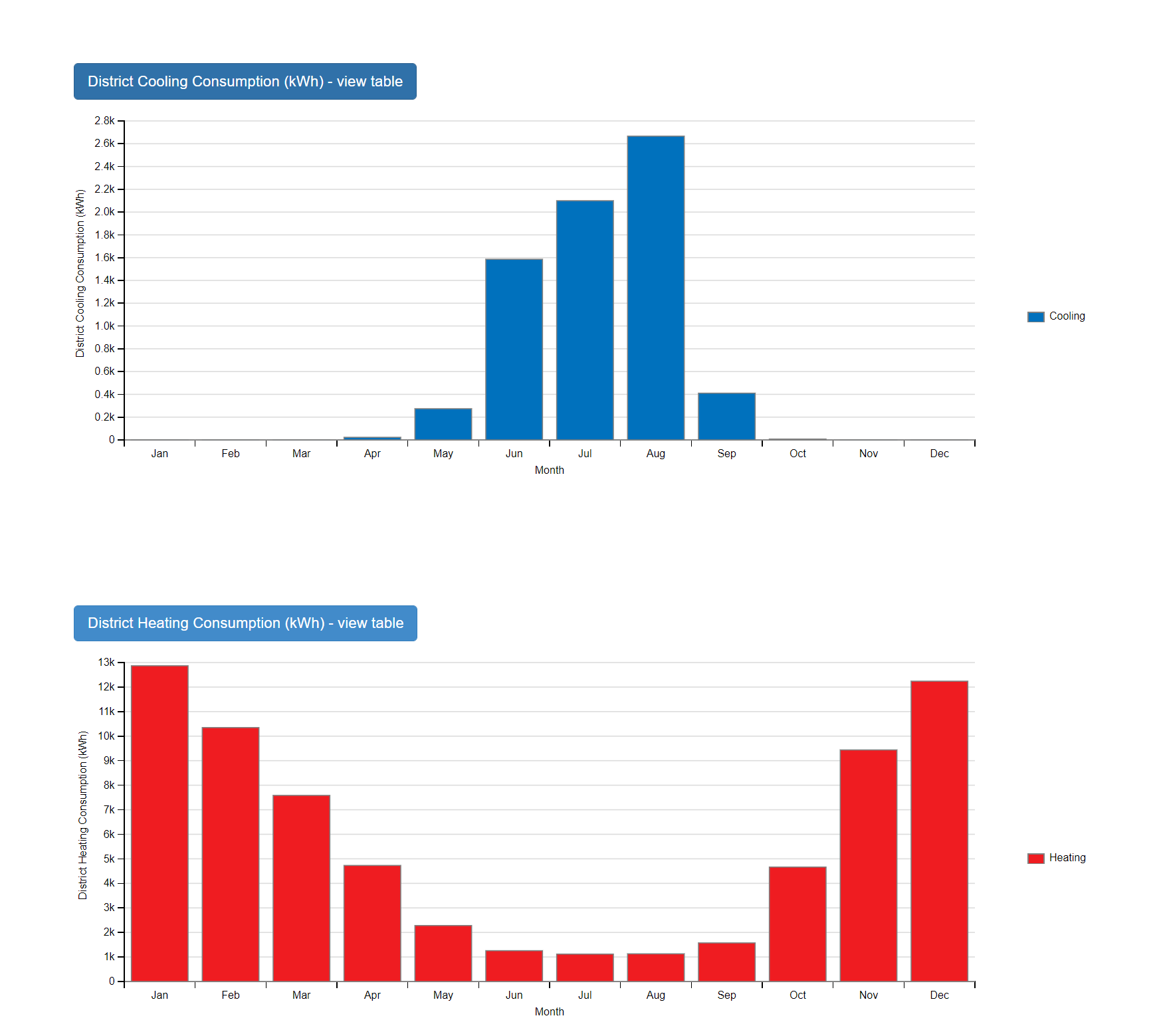
So I don’t think the error is with the pollination simulation or with your model setup but rather whatever is happening locally to build that LoadBalance graph from the Pollination results. There’s probably some extra output that’s being accounted for in the results that’s causing the results to be mis-calculated.
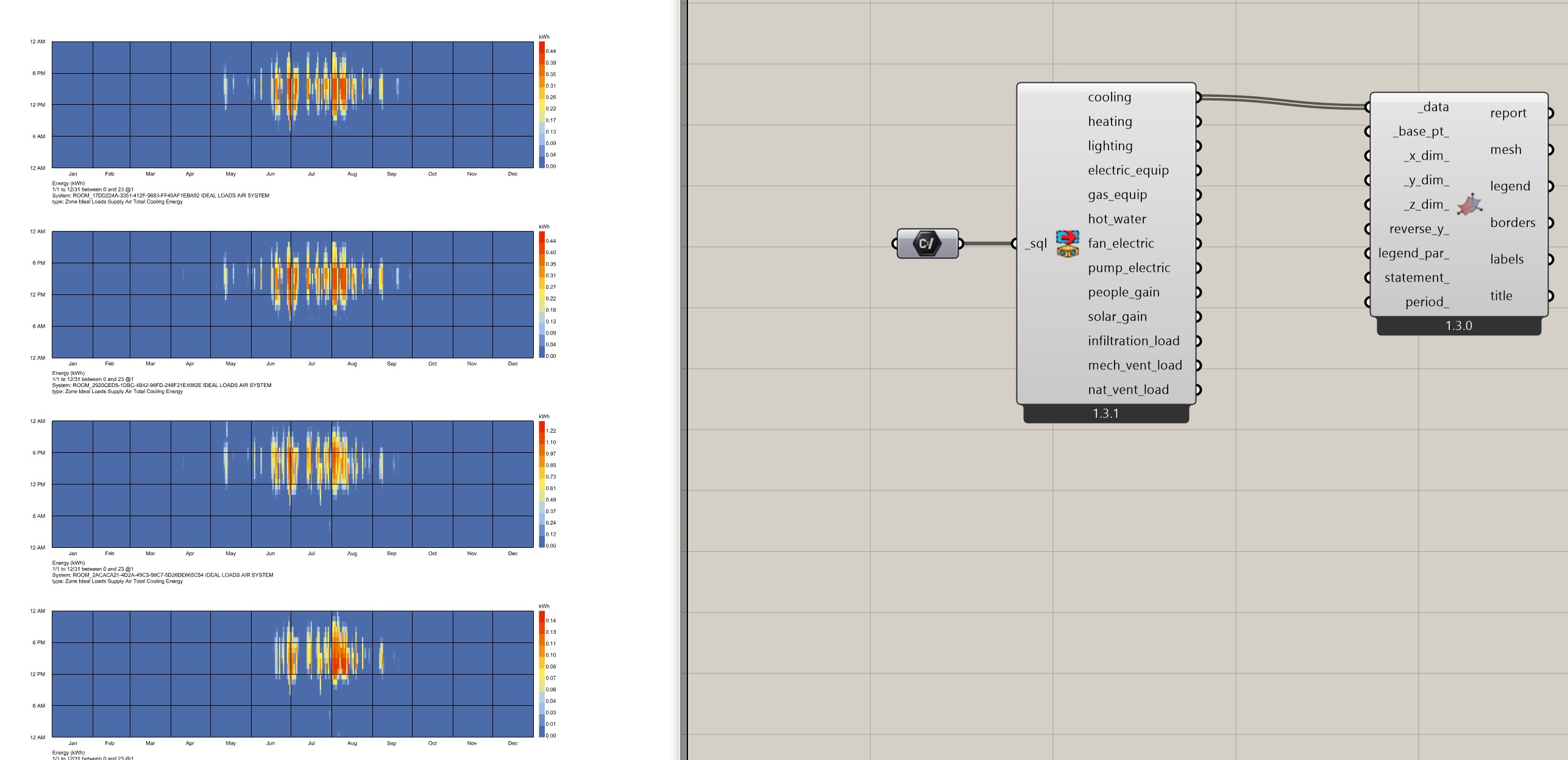
I was planning to add a dedicated recipe for producing LoadBalances since you really need both the Model and the results to follow a specific format (and usually exclude certain types of outputs) in order for all of the postprocessing to work correctly.
I’ll take a look at your .sql file when I get the chance but, for the time being, I recommend using the custom-energy-sim recipe if you need to construct an energy balance like this and then use the future dedicated recipe for load balances when it’s available.
Yes, this has to do with the OpenStudio Results measure (that generates the nice HTML report in the annual-energy-use recipe) interfering with the format of the SQL. I’ll add some checks for this type of differently-formatted SQL when I get the chance but just using the custom-energy-sim recipe should avoid all of this weirdness since that recipe doesn’t include the report.
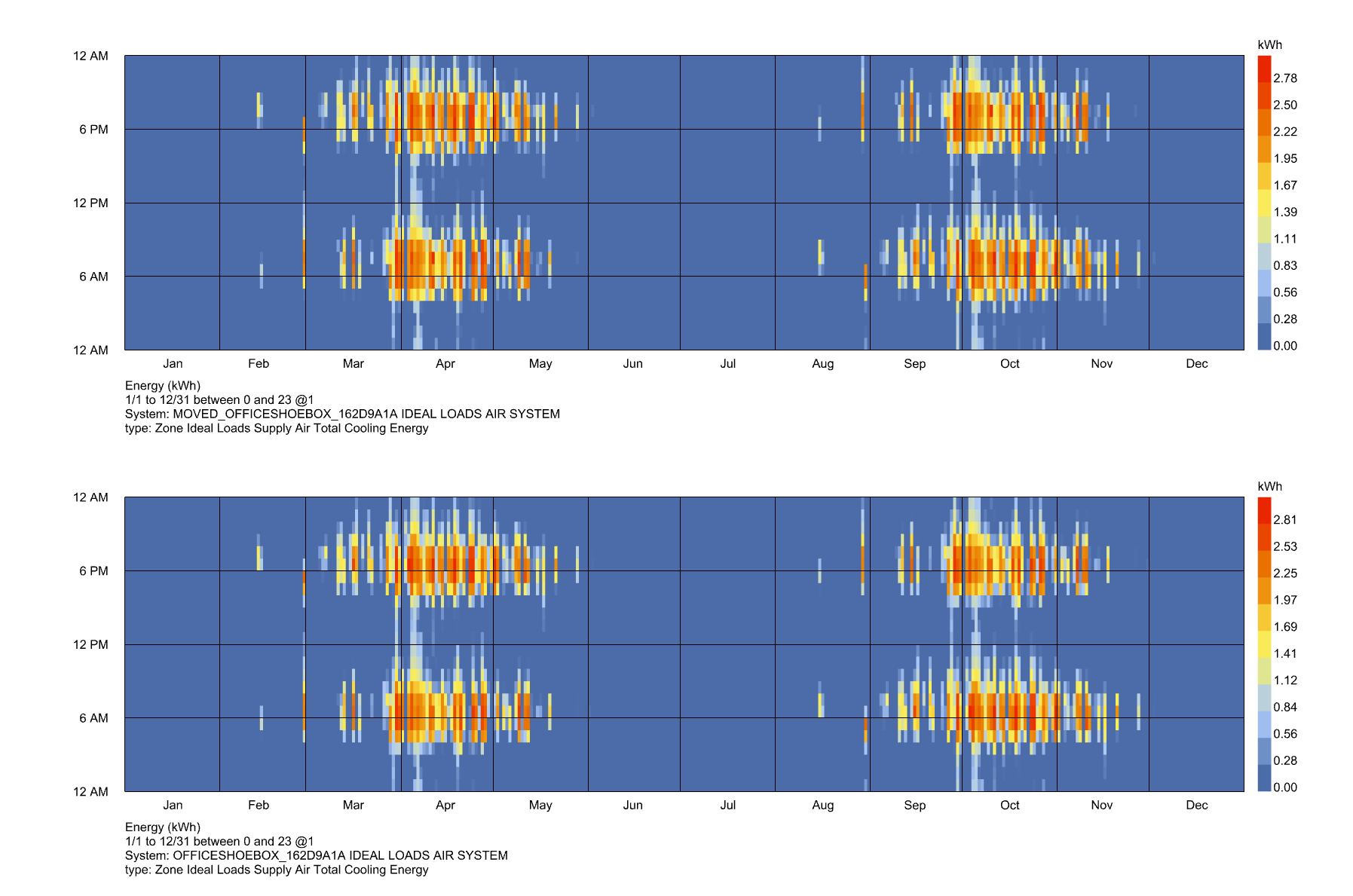
And I was correct that the EnergyPlus simulation ran fine and the results are valid in the annual-energy-use recipe. They’re just not imported in the right format by the LBT plugin on the local side of things.
Ok, I just pushed a fix that should ensure that the LBT plugin can import the SQL data in the correct order even when the OpenStudio Measure changes the format of the SQL:
I tested it with the .sql file on @martin6 's project and it now loads the SQL data correctly:
I’ll warn that the fix noticeably increases the run time of the SQL result-parsing components when you load a lot of data, like the ~5 million data points (8760 * 40 * 16) being loaded with this particular SQL and the “HB Read Room Energy Result” component. But this is what’s needed to avoid incorrectly-formatted results whenever OpenStudio reporting measures request other outputs to be written to the SQL.
The fix should be available with the “LB Versioner” in an hour or so.
FYI, I implemented something that should mitigate the run time for large files:
It seems Python 3 is much more efficient at running this type of sqlite query than Python 2 so, whenever we have a large sql file, we just use the honeybee-energy CLI with Python 3. When the SQL file is small enough , the overhead of calling Python 3 isn’t really worth it so we still use the SQLite module in IronPython for this case.
But the change above drops the runtime of this 5-million data point import from 6 minutes to 2 minutes. So it seems worthwhile.