Hello,
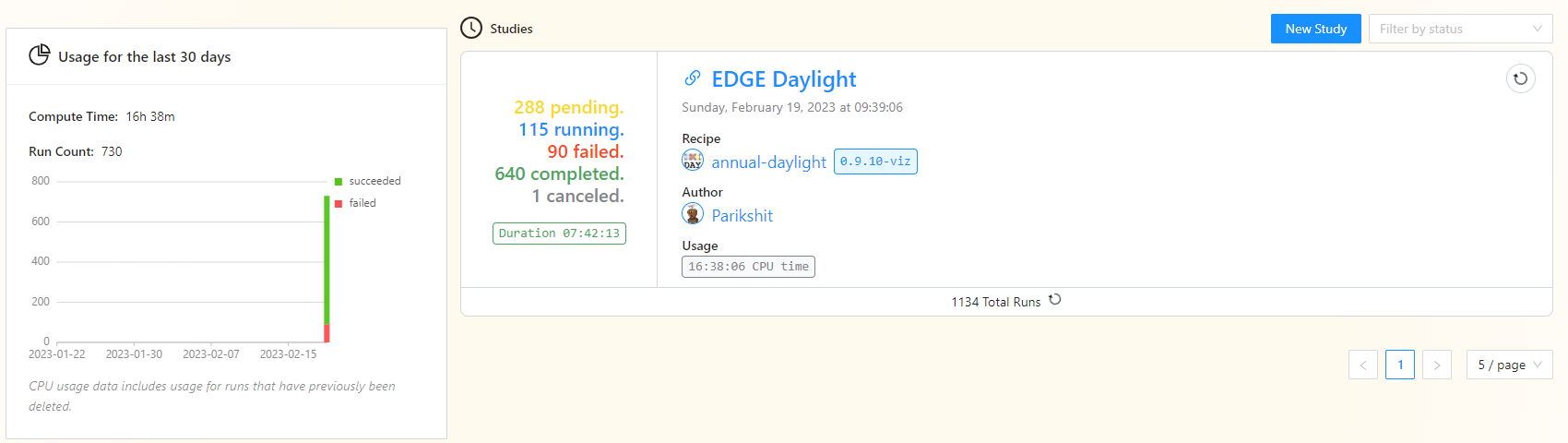
I have large simulation, around 1134 variants. I started the run, after few minutes I saw few “failed” studies. So I decided to stop the simulation (right clicking the status component_“cancel this job”). But apparently the job is still running after 6 hours.
I saw few successful simulation so I let it run. But then after few hours the status has not been changed. The GH status component shows that the job is still running.
So I am confused whether to let it run further or cancel the study. And if I want to cancel, how should I do that?
Hi @parikshitnik - Thank you for documenting the issue.
The reason that you see the pending runs is a bug from Argo which is the technology that we use under the hood. If you are interested in technical details here is what is happening:
Workflow hangs after clicking stop and terminate · Issue #10491 · argoproj/argo-workflows (github.com)
I know it is a terrible user experience, but the good news is that this time will not be charged to your account. Once you send the signal the workflow stops running but Argo fails to update the status of the workflow and so Pollination shows them as still running. We are working with the developers of Argo to resolve this issue as soon as possible.
Now, going back to your studies, I suggest grouping them in smaller patches that is closer to the number of CPUs that you have (currently 120) otherwise many of them will be there hanging for a very long time before the resources are available. This is an item that we will improve in the future to handle the queuing process on our end.
@mostapha Thank you for resolving this!
I see the run is cancelled now. The stats shows that it took around 18 CPU hours. However when I checked the subscription, it is showing me 148 hours of consumption.
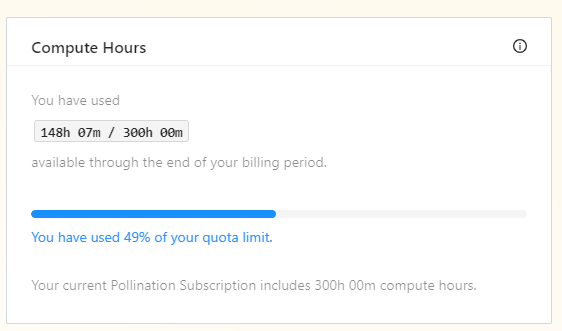
is this because of the study was hanging there for long time?
If possible could you please add the hours back? Next time I will run them in smaller chunks!
Both items in this discussion have been addressed for some time now. The Argo bug is fixed, and we have switched the resources to use the logs from Argo.