Hi,
For some reason I’m unable to load a large number of runs as one job.
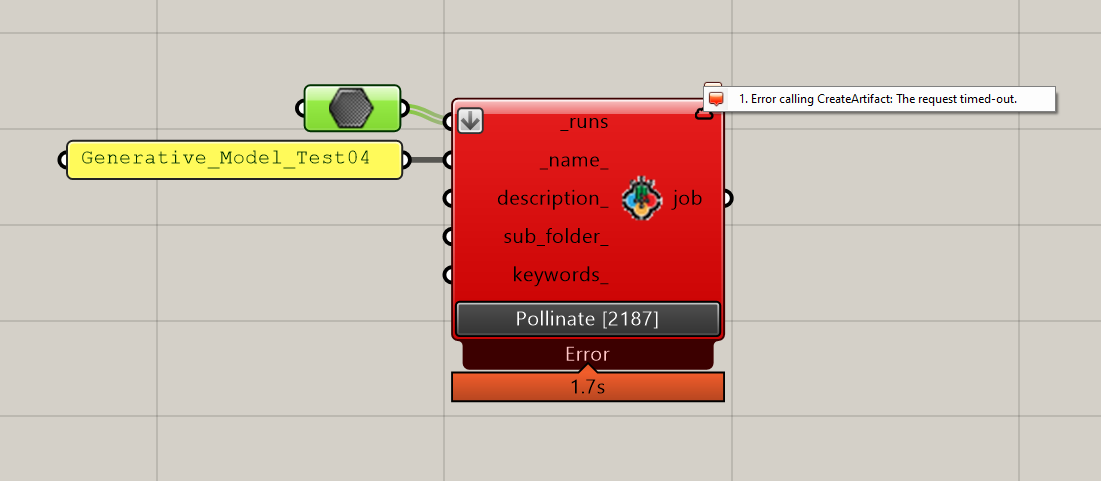
When trying to upload 2187 runs after a couple of minutes of uploading I get an error “Error calling CreateArtifact: The request timed-out.”
These same runs load successfully when divided into two parts, however my final goal requires a lot more simulations, which makes this approach difficult to use.
What is the cause of this problem and is there a more convenient and faster way to upload runs to the server? Thanks!
The Grasshopper plugin tries to do a few tasks together and that can become a bottleneck in cases like yours. In particular, in a standard workflow, you can upload the files to Pollination first and then reference them in the runs.
Our initial hope was that users will customize the recipes so for example like this you would have uploaded all your geometry scenarios and then use a recipe that looks up the folder and starts the runs. In that case, because the files have been already uploaded to Pollination, they can be picked up by each run without facing issues like the one that you are facing here.
@mingbo, is the time-out limit something that we can increase to avoid scenarios like this?
@mingbo and I have talked about this a few times. I don’t think increasing the timeout will solve the problem, as there will always be larger studies with more files.
I think we should either change the process to upload the files one by one and update the runs to use those files similar to how we do it in the sample workflows like this (How to submit an energy simulation to Pollination using the API - #9 by mostapha) or provide a solution to upload the files separately to your project first, and then use the reference to those files to set up the runs quickly.
You can use a Python script similar to this one here to submit large studies.
I also know that @mingbo started breaking down the steps for uploading the input files and setting up the runs. Once that is ready you should be able to set up larger runs from Grasshopper too.
Oh great !! I will check this out.
Also, I wonder if this script would help download or read the results faster. Compared to the current workflow with ladybug fly or Collibri iterator to read through all the jobs.