Here I explain better my previous question:
I am currently working on a project where we are using Dragonfly in Grasshopper to create scripts for simulating neighborhoods based on building footprints and customized programs. Our primary objective is to obtain hourly energy demands and thermal powers for each building through simulation.
As we progress, we are facing challenges with local simulations, as the process is quite time-consuming. Running simulations for approximately 200 buildings takes up to 4 hours, and in some cases, the simulation abruptly stops, leaving around 100 buildings unsimulated.
In our quest for a more efficient solution, we have come across Pollination and its cloud capabilities. We are eager to explore the possibilities it offers to speed up our simulations and improve our workflow. However, we have some concerns regarding certain aspects of the platform.
Specifically, we are uncertain about how to modify recipes, such as adding mappers or incorporating additional fields in the GeoJSON to capture results like annual demand or thermal loads for each building. Additionally, we would like to understand better how CPU time usage is calculated and the options available for cloud capacity.
To address these uncertainties and ensure we make the right decision for our project, we kindly request your assistance in guiding us through the process of choosing the most suitable Pollination product.
We anticipate that we may need to upgrade to the Basic level of cloud capacity, considering the scale of our simulations.
Thank you very much for the update. This is already the solution to my initial problem.
Exactly, I am using URBANopt (through the “run urbanopt” command in Dragonfly). At the moment, not using URBANopt won’t be an issue. We use these results to size district heating networks with SIM-VICUS (an open-source tool for sizing networks up to 5G), and we are currently trying to automate the transition between Dragonfly and this program. We are also keeping an eye on the progress of operability with Open Modelica (as you already know from the Ladybug Tools forum). However, we have doubts about whether OpenModelica will be useful for us, as it has such a high level of detail and complexity for modification and sizing that we believe it won’t be practical for commercially sizing district heating and cooling networks.
Thank you very much, @mostapha . Initially, we are particularly interested in the post-processing part, which involves creating fields in the GeoJSON with the results of the loads and demands for the buildings, as well as generating files with hourly data for heating and cooling demands. As for modifying the inputs, it would mainly be to include the mappers.
Using mappers, we are currently working on including the effect of thermal bridges with the TBD measure. I have been reviewing the Ladybug forum, but I haven’t found a better solution. We are modifying the U-values of each building based on the year of construction and this measure.
And lastly, thank you very much for the explanation about the CPUs. Initially, the simulation I conducted was at the Story level, and I understand that each apartment would be considered a CPU, which is why the CPU resources of the free version were consumed so quickly. I think we will have to consider upgrading to the building level plan since we are currently sizing district heating networks at the building level. However, at some point, we will also move to the plant level.
Thank you for the clear explanation. @chriswmackey already responded to most of your questions on the other topic.
I moved the conversation here to keep it separate from the other discussion about updating the recipe.
The easiest way for us to be able to help you is by using an example file that shows how you manage all these changes when using Grasshopper. Also, an estimate on the number of runs, and possible parameters that you might need to change for running those cases.
We have helped several customers with customizing the recipes for their specific use cases. It is possible to add pre and post-processing to the existing recipe. Depending on what you are trying to do we can identify which parts should be included in the recipe and which parts are better suited to be done locally.
You should feel free to email us or start a private message if you can’t share your model/script publicly.
After @chriswmackey 's advice, we have reached the point where the best recipe for my case is the “custom-energy-sim.” Regarding post-processing, I tried to download the SQL files directly in Grasshopper, but it indicates that I can only connect one item. I understand that this happens because different runs are performed in a single study. Returning to the objective of my post-processing, I need to obtain the SQL results to use them in other district heating and cooling simulation programs. I would need to export the hourly demand for heating, cooling, and domestic hot water (ACS). Additionally, I need to extract the peak powers since the study includes two types of simulations: annual (with timestep 12) and sizing (with timestep 2).
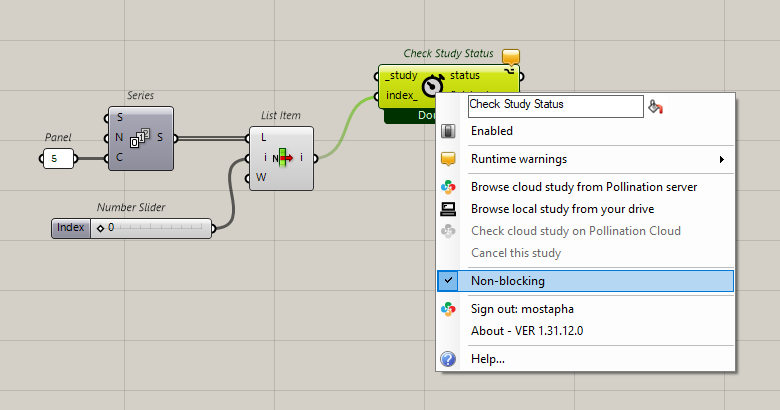
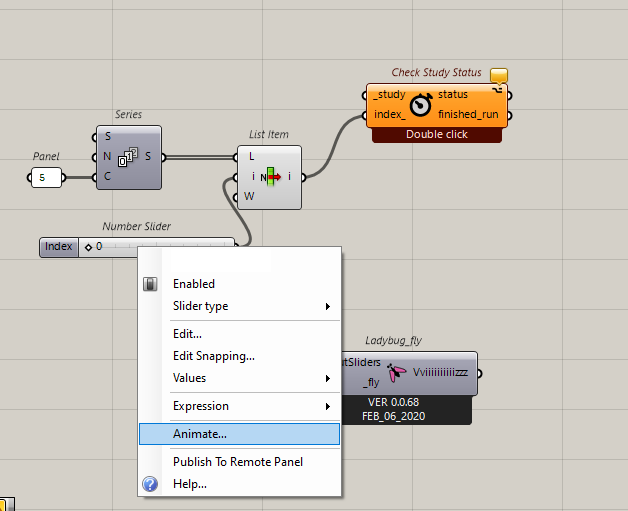
You should try a slider and animate it. Or you can use the fly component. You should also right-click on the Check Study Status and Load Assets and make sure they are in the blocking mode so the Grasshopper script doesn’t start a new solution before downloading the first one.
In your case, you only have to do it 5 times. You may want to just change the value manually. Make sure that you save the files in separate subfolders or with different names so they don’t overwrite each other.
Thank you very much for the solution. I have successfully imported everything. Currently, I only have 5 runs, but the plan is to expand to more. However, I can’t seem to find a way to name each run with an ID to easily identify (in this case) the building. I thought adding a “name” in the user_input would work, but when I download the SQL files, they are saved in folders with random names. Is it possible to assign a specific name to those folders?
That is expected. The ID is the ID of the specific run. You can use the “name” to save them in a different folder or rename them as needed in Grasshopper.
Here is a sample file. I didn’t realize your projects are public. That made it easier to build a sample. I use the ID that you assigned to each run to rename the sql.